
Reading time: 2 minutes
For the second paper of my PhD (Astronomy & Astrophysics, accepted), I made a catalogue of star clusters using data from Gaia DR3. It was a huge, huge undertaking, with a total of 729 million stars used as input and a whole range of machine learning methods used to analyse it all. Here’s a quick summary of the paper (before I show you some plots.)
Star clusters are hugely useful in astronomy, with open clusters in particular (my research interest) being used for lots of different purposes: like studies of stellar evolution, studies of our galaxy’s structure, or calibrating standard candles used in cosmology (like Cepheid variable stars). So it’s safe to say that having good-quality catalogues is important, which is why we set out to make one - leaving no stone unturned to make it as good as possible!
Maybe the coolest thing about the paper is the approach. Nobody has ever tried to make such a wide-ranging catalogue of star clusters from a blind search before: the big advantage of blind searching is that we end up with a 100% homogeneously processed catalogue. Thanks to my work in my first paper, we know that HDBSCAN is the most sensitive algorithm, meaning that we’re able to redetect virtually all reliable clusters available in Gaia data in one fell swoop, both finding new clusters and deriving new and improved membership lists for existing known ones.
The catalogue is very stringently processed, with a statistical density test used to validate the density of clusters and a neural network used to test how coeval each population seems based on its colour-magnitude diagram. These are published as statistics in the final catalogue, allowing users to set their own limit on how good cluster candidates need to be for any further analysis. In addition, the catalogue also includes distances, photometric parameters like ages and extinctions, and approximately estimated spatial parameters (King radii).
Finally, it’s worth noting that another paper is coming soon to further process our results. A lot of the clusters we detect are more compatible with moving groups; these will be classified properly with a more sophisticated method.
Here’s a summary of the results in plot form.
A high recovery rate of known clusters, in addition to 749 high-quality new candidates

High quality membership lists down to G~20, often including tidal tails and other features

Surprising new objects, like this new star cluster that has been hiding behind one of the most famous open clusters for centuries

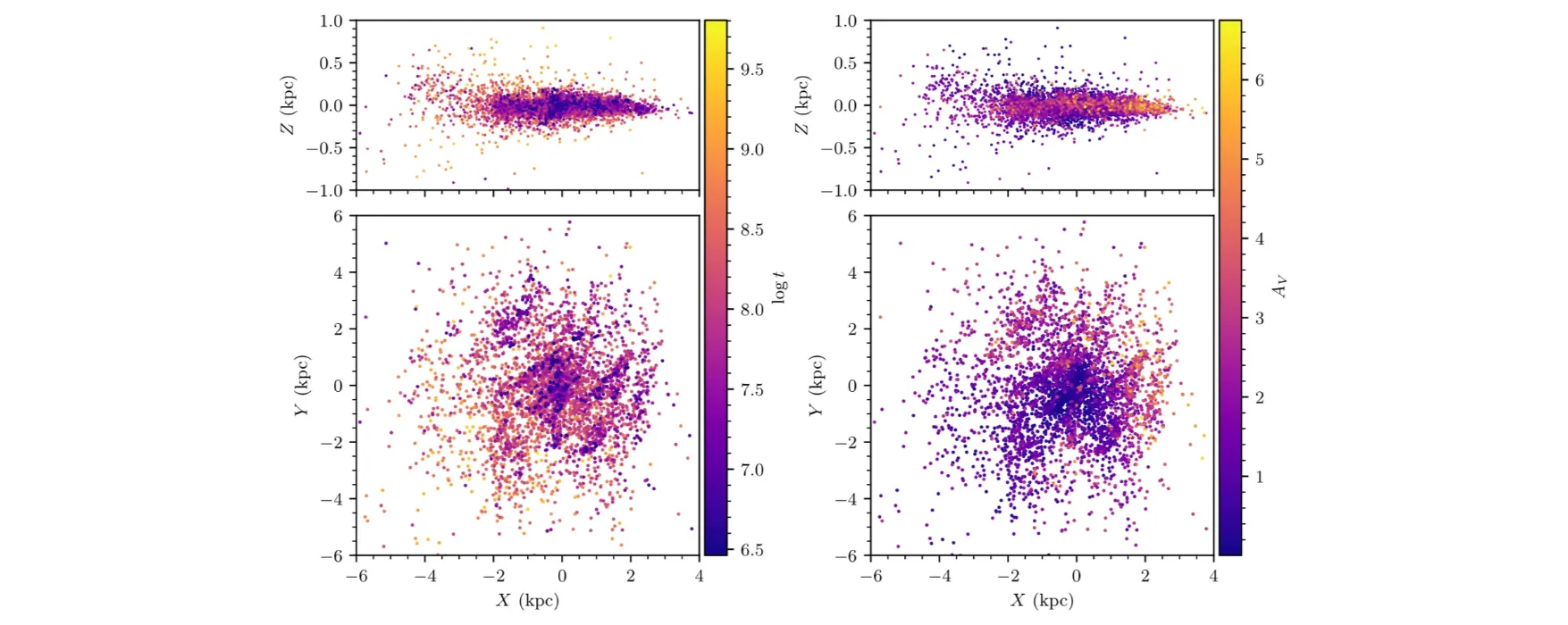
Homogeneously derived parameters for ~7000 clusters, tracing the structure of the galactic disk

… and analysis on why many literature clusters aren’t detected
(spoiler alert: many of them probably aren’t real)
