with machine learning, statistics and software
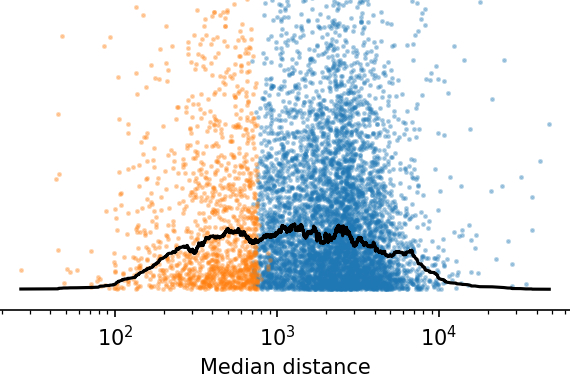
The Gaia satellite is revolutionising our understanding of the Milky Way, with around 1 billion reliable sources in the latest release (DR3). Thousands of star clusters can be found within this data, but doing so requires efficient ways to autonomously and reliably search through it. I used clustering algorithms to create the largest ever catalogue of star clusters within our own galaxy.

It's important to not only catalogue star clusters but to do so as reliably as possible. To enhance our catalogue, I'm working on statistical ways to validate star clusters based on their density, photometry, and dynamical properties. This uses a range of techniques, including a Bayesian convolutional neural network and a statistical model for whether or not a candidate cluster is gravitationally bound.
Open source software has been key to my PhD, and I'd really love to give some things back to the community. All of the code from my PhD will be open sourced in the near future - watch this space! In addition, I'm currently developing open source software to help astronomers communicate on the Bluesky social network.

Here's some other stuff I did before my PhD.
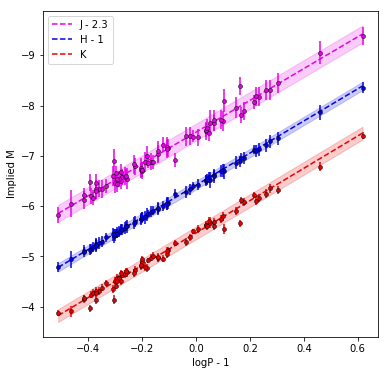
For a summer internship, I wrote a Bayesian inference pipeline to determine extinctions and a PL relation for Milky Way Cepheids.
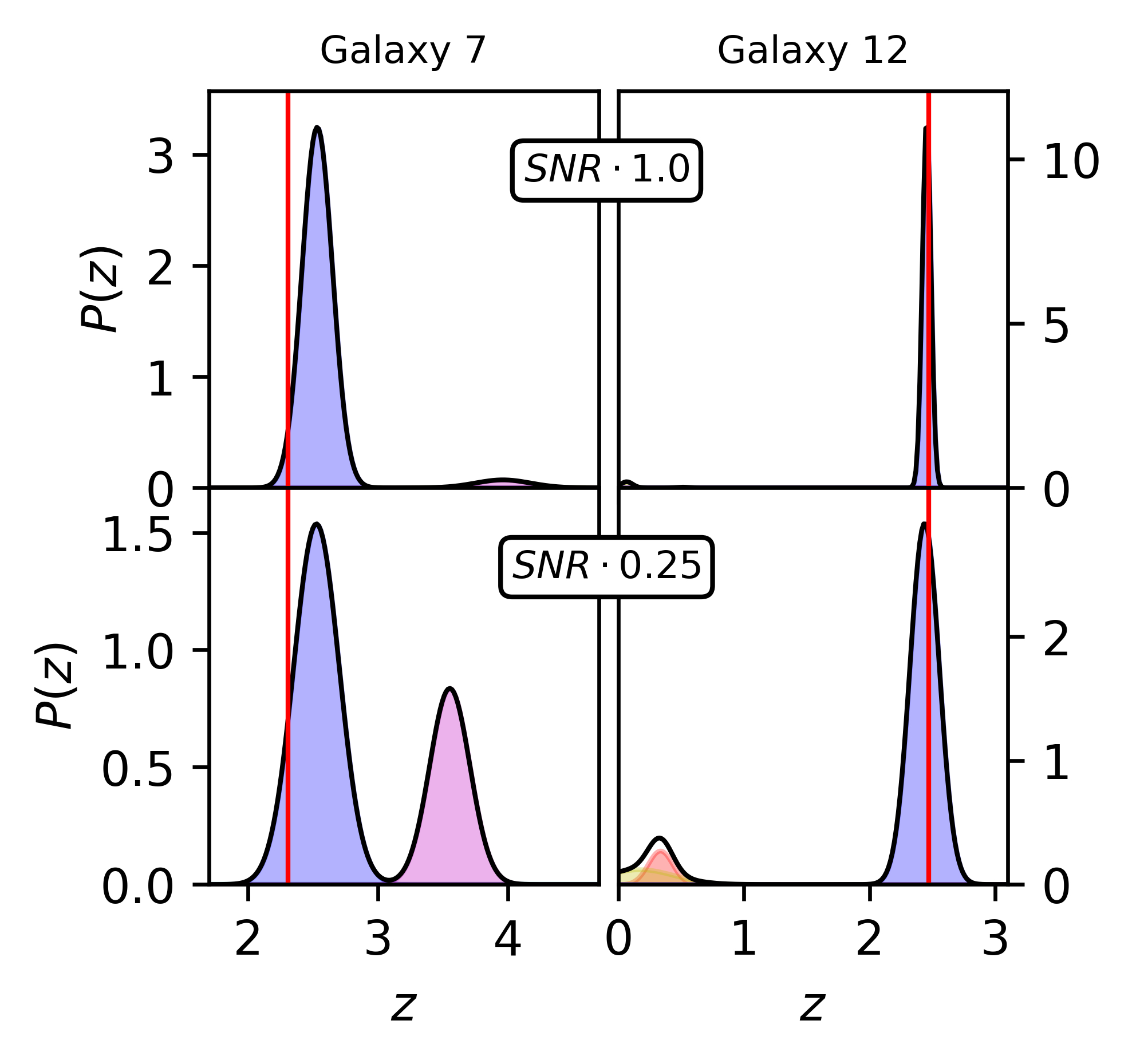
For my master's project, I trained a neural network to infer redshifts from photometry without requiring human-defined models.